Personal data remains attractive for malicious actors and cybercriminals. As they evolve their methods for stealing and compromising such data, implementing sufficient data protection measures is especially vital for any organization.
In some industries, protecting personal data is a must to comply with privacy laws and regulations. But even if your organization is not subject to a particular data privacy requirement, it’s highly recommended to secure the data of your customers and employees.
This article reviews why personal data needs advanced protection and how pseudonymization can help your organization improve data security.
Why is protecting personal data so important?
Personal data is any type of data that can be used to identify a specific person, whether on its own or in combination with other data assets. Another term used to refer to this kind of data is personally identifiable information (PII).
There are two types of personal data that can be used for identifying a particular person.
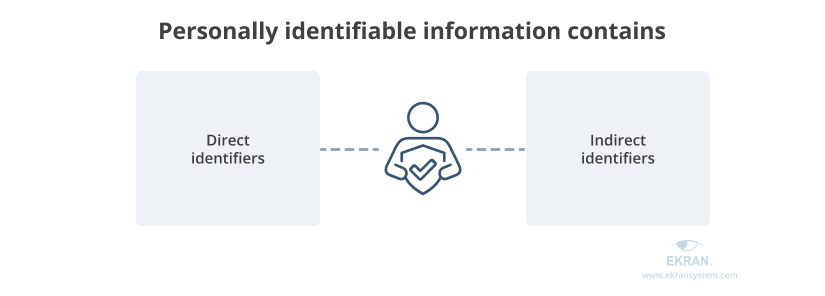
Direct identifiers are data that can help to accurately identify the person the data belongs to. This information includes name, email address, telephone number, social security number, bank account number, and other unique personal details.
Indirect identifiers are pieces of information that aren’t unique enough to identify a person immediately but that can lead to identification when used in combination with other data. They include age, location, race or ethnicity, and distinctive characteristics such as a rare health condition.
Organizations need to protect both direct and indirect identifiers. We review the reasons below.
10 Data Security Best Practices: Simple Steps to Protect Your Data
Why do organizations need to protect personal data?
Personally identifiable information of an organization’s customers and employees is an attractive target for cybercriminals. Usually, they aim for personal data so they can use it for identity theft, fraud, social engineering, or other malicious activities.
To prevent criminals from stealing personal data, governments and institutions worldwide have implemented various data privacy laws. Non-compliance may lead to enormous fines and sometimes even criminal liability.
Besides, falling victim to personal data breaches is costly on its own. The 2020 IBM Security report shows that breaches of customers’ personally identifiable information are the most expensive, with a $150 average cost per record. Not to mention that it’s hard to predict the actual financial losses your organization will face due to reputational damage caused by a data breach.
One way to ensure proper protection of private data is pseudonymization. In the next part, we review what pseudonymization is and how to pseudonymize your data.
What is pseudonymization and how does it work?
Pseudonymization is a way of processing data that makes it impossible to identify who the data belongs to without the use of additional assets.
This method de-identifies data by replacing the original information (name, address, or phone number) with an alias or pseudonym. Thus, pseudonymization reduces the risks of exposing personally identifiable information to unauthorized users.
However, pseudonymization is reversible and supports the re-use of pseudonymized data for new purposes. Whenever an authorized user requires the original data, they can re-identify it.
When pseudonymizing personal data, organizations assign pseudonyms to direct and indirect identifiers. After that, the collected information is stored under pseudonyms in one database, while the information about the true identities behind the pseudonyms is stored in another.
In addition, the database with pseudonymized data is accessible to all people working with PII. But the database with decrypted pseudonyms can only be accessed by a limited circle of people. Hence, only those who have access to both databases can re-identify owners of the collected PII.
Common pseudonymization techniques
There are several approaches to pseudonymizing personal data.
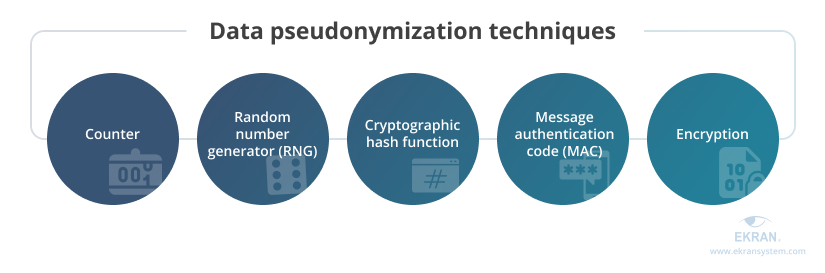
Counter – Substituting identifiers with a number generated by a monotonic counter is the simplest pseudonymization technique, and it doesn’t cause collisions – cases when two identifiers are assigned to one pseudonym. However, it only suits small and simple databases.
Random number generator (RNG) – When replacing identifiers with random numbers generated by either a random number generator or a cryptographic pseudo-random generator, collisions may occur because there’s a chance of different pseudonyms being assigned the same number.
Cryptographic hash function – Generating a fixed length value to replace identifiers in personal data is a collision-free method, but it’s prone to brute-force and dictionary attacks.
Message authentication code (MAC) – This method involves creating pseudonyms for identifiers using a special chunk of data called a secret key. The same key is used to map pseudonyms back to identifiers when there’s a need to decipher the protected information.
Encryption – This involves using block ciphers to encrypt identifiers using a cryptographic key. As with MAC, the same key is used both to re-identify data and recover encrypted information. This technique requires some effort to adjust identifiers to a specific size, since the size of blocks is fixed.
When choosing a pseudonymization technique for your organization, make sure to avoid those techniques that let users easily map pseudonyms with actual data and re-identify personal data without additional means.
Personal data pseudonymization can sometimes be confused with another data privacy protection method — anonymization. Let’s find out more about anonymization and how it differs from pseudonymization.
5 Industries Most at Risk of Data Breaches
Anonymization vs pseudonymization
The terms pseudonymization and anonymization can sometimes be used interchangeably, but they have different meanings.
Anonymization removes the association between private data and a specific data subject. Anonymization is a one-way process: once information is anonymized, no one can re-identify the information and define who it belongs to.
The core difference between pseudonymization and anonymization is the way they work. Pseudonymization de-identifies data while preserving the possibility to re-identify it later. In contrast, anonymization de-identifies data once and for all.
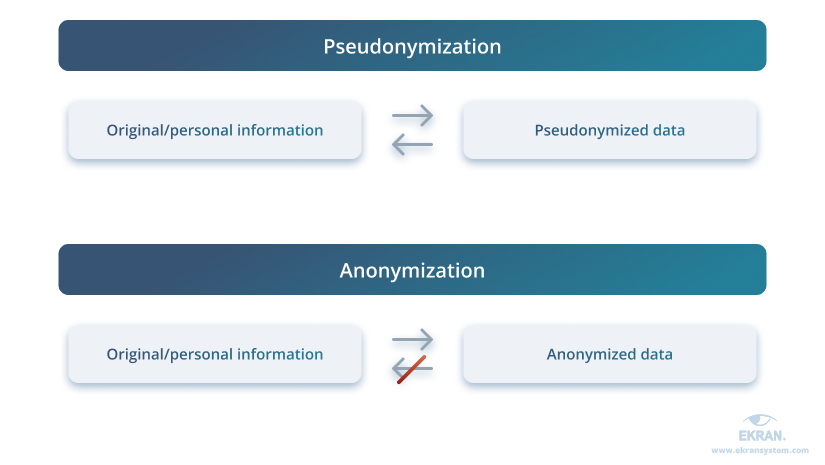
Full data anonymization is hard to achieve, as it’s difficult to ensure that the results of anonymization cannot be re-identified through any means. In addition, not being able to re-identify data might be inconvenient in some cases: for instance, when investigating cybersecurity incidents.
Pseudonymization, in turn, enables organizations to efficiently protect the privacy of their customers and employees while also maintaining the ability to access any crucial details in times of need. Let’s look at five reasons why you might consider implementing pseudonymization to secure valuable personal data handled by your organization.
5 reasons to protect personal data with pseudonymization
Organizations have a lot of reasons to use pseudonymization and other methods to protect the data they collect and process. Among those reasons, we’d like to highlight the following five:
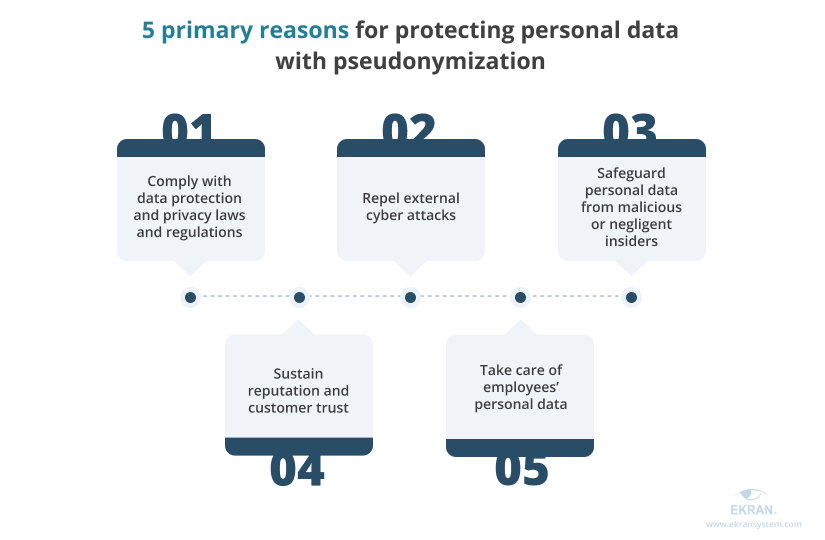
1. Comply with data protection and privacy laws and regulations
Protecting personal data is a requirement of many laws and regulations. The list of those your organization needs to follow depends on where your organization is located, what industry you work in, and what types of private data you collect, store, and process.
Here are some of the major laws and regulations that oblige organizations to protect PII:

The General Data Protection Regulation (GDPR) is a regulation on the privacy and protection of personal data of individuals residing in the European Union (EU) and European Economic Area (EEA).
10-Step Checklist for GDPR Compliance
The Data Protection Act (DPA) 2018 is the United Kingdom’s implementation of the GDPR, aimed at protecting the privacy of British residents’ personal data. Even though the GDPR and DPA 2018 have a lot in common, they differ in some aspects. For instance, per the GDPR, the minimum age of consent for processing personal data is 16, while in DPA 2018, it’s 13.
The Health Insurance Portability and Accountability Act (HIPAA) is a US law that specifies the flow of healthcare information in the United States and indicates how healthcare providers should protect their patients’ PII. Dedicated healthcare compliance software solutions can help you meet the requirements of this act.
The California Consumer Privacy Act (CCPA) is a California statute signed into law in 2018 that protects the privacy rights of California residents.
Although the GDPR and the three laws mentioned above differ, each requires organizations to pseudonymize or, put another way, to de-identify personal data they collect, store, and process.
GDPR compliance systems and other compliance solutions can help you prevent personal data breaches and, therefore, avoid fines and criminal charges.
Ekran System is an insider risk management platform that can help your organization meet the requirements of leading international, local, and industry-specific IT security standards, laws, and regulations.
Meeting IT Compliance Requirements
2. Repel external cyber attacks
Organizations that store and process PII of their employees and customers are often a target of cybercriminals. According to the 2022 Verizon Data Breach Investigations Report, personal information accounts for 37% of all data compromised during system intrusions.
By pseudonymizing PII, you lower the risks of disclosure and compromise of your customers’ and employees’ data even if attackers manage to steal data assets. This is because properly pseudonymized data cannot be re-identified without additional data assets.
Ekran System offers real-time incident response functionality to help you detect and deter malicious attacks. It includes user and entity behavior analytics (UEBA), predefined and custom alerts, and automated notifications, warnings, and actions.
7 Cybersecurity Challenges to Solve with a UEBA Deployment
3. Safeguard personal data from malicious or negligent insiders
A threat to the PII that your organization processes can also come from current or former employees. Some of them may have malicious intentions towards sensitive personal data out of a desire for financial gain or revenge on your organization.
By pseudonymizing PII and making sure that only people you trust can access sensitive data, you can reduce the risks of personal data breaches and leaks.
To prevent and promptly identify malicious actions performed using insider accounts, Ekran System provides organizations with advanced user activity monitoring with video format session recordings indexed with metadata. As well, Ekran’s privileged access management (PAM) features allow organizations to limit users’ access to critical assets and helps implement various access control models, such as mandatory access control (MAC) and discretionary access control (DAC).
4. Sustain your reputation and customer trust
Organizations devote a lot of time and effort to building customer trust. However, personal data breaches often lead to the deterioration of an organization’s reputation and loss of customer trust.
The results of the 2021 IBM Consumer Survey show that privacy (38%) and security (41%) concerns are the top reasons to avoid using apps or websites to shop online.
By using data pseudonymization and other means for data protection, you minimize the chances of data breaches in your organization and, consequently, lower the risks of reputational damage.
In particular, apart from pseudonymizing PII, you can consider implementing a third-party vendor monitoring solution to pay more attention to how your partners and outsourcing service providers handle personal data collected by your organization.
5. Take care of your employees’ personal data
Your employees entrust your organization with a wide variety of personal data. Unlike your customers, they don’t even have a chance to refuse to share their PII, since that information is often required for the hiring process as well as for further cooperation. Since your employees’ PII can also become a target of cyber criminals, it needs strict protection.
During regular cybersecurity training, you can inform employees about the data protection measures you take so they can rest assured that their data is safe and sound. It also can help you build a reputation as a reliable employer.
Ekran System gathers tons of information on employees and their activity in the organization’s network. Its data privacy protection functionality makes sure that employees won’t have their privacy compromised when someone accesses and views session recordings or logs. However, re-identification is still possible for users with corresponding permissions for the sake of effective incident investigation.
Cloud Infrastructure Security: 7 Best Practices to Secure Your Sensitive Data
Conclusion
Protecting personal data is is aimed at ensuring the security of your customers’ and employees’ PII. Both anonymization and pseudonymization can assist you in implementing a sufficient level of private data protection in their unique way.
However, a comprehensive data protection strategy requires more than just anonymization and pseudonymization. You may also consider limiting access to assets with PII, monitoring the activity of privileged and regular users as well as third-party vendors, educating employees on the importance of data protection, and deploying a dedicated software solution.
Ekran System is insider risk management software that comes with potent functionality for enhancing your organization’s data security. It gives you complete visibility into the actions of privileged users, allows you to automate incident response, and helps you comply with data privacy requirements in your industry.
Start a 30-day trial to see how you can address the risks of personal data theft and compromise with the Ekran System platform.
Share:




